Vibe-Coding as a VC: We Need to Eat Our Own Dog Food
A boiling-hot summer didn’t stop my token frenzy on vibe coding, reshaping our fund into an AI sandbox, and deepening my passions for entrepreneurship, tech, and product.

Those vacations were the most intense I’ve had in a while. Time off is always the chance to focus on building knowledge or skills, whether for personal enjoyment or for work. And this summer break was the perfect moment to disconnect from the hectic daily routine, the endless flow of emails and back-to-back meetings, and dive into introspection.
Walk the Talk
Our job is to look for AI-native companies (post-LLM startups), because we believe they are a different breed, born in a different world. Which begs the question: what about us? Why should funds be any less affected by this new paradigm? Could we be an AI-native fund, making moves as fast as the companies we invest in? And if we could start from scratch, where would we start?

August 2nd. I was alone in a tiny, windowless room in Hongdae, Seoul, while it was 35ºC outside: zero distractions, almost no family duty, and surrounded by konbinis open 24/7. It was the perfect setup to switch into full focus mode (some would call it *berserk* mode), locked in for almost 22 hours a day with bare sleep. I started testing nearly every tool, API, and flavor of AI coding - tap coding, vibe coding, agile coding, spec-driven coding, you name it - until I found my own pace and recipe. Then I literally went on a token frenzy, on a quest to turn our management company into an experimental sandbox with one clear goal: to make our workflow more efficient, more personalized, more agile, and more collaborative.
Tale From the Neolithic (circa 2022)
Sounds familiar, doesn’t it? It’s basically every company’s dream. And of course, it was our initial vision too, until reality struck. Four years ago, we started with a fancy yet incomplete home-made platform using Ruby on Rails, VueJS 2, and Postgres. I built it during the fundraising phase (yes, investors raise money too), but things went south pretty quickly once we began investing which left me absolutely no time to refine and upgrade the platform. A small fund faces the same workload and regulation as a large one, only with far fewer people to handle them.
I then decided to move to Airtable, which allowed me to add features quickly through scripting and required almost no maintenance. Our data feeding was inconsistent, and we believed a robust CRM was the answer. So we migrated to Pipedrive, with its out-of-the-box Google Suite integration, thinking this would finally bring auto-feeding.
We were dead wrong. A few months after deployment, I had opened Pipedrive exactly once. Willy, probably less. I believe the real issue lies in the CRM model itself. They are powerful tools when they are perfectly fed, but nobody wants to feed them. And nothing is worse than inconsistent structured data. I also believe that, even with absolute dedication, this state of perfection does not exist. I have wrestled with taxonomy my whole career. Movies at AlloCiné. Games at Gamekult. Both at SensCritique. And later startups at daphni. It is a never-ending pain. Categories keep shifting labels, especially in our ecosystem. They are hard to define, and people rarely share the same framework or even the same depth of expertise.
In a world where a new model emerges each month, sometimes week, it became obvious we needed to move at the same speed, and be part of this evolution. Be leaner, yet enhanced. We now firmly believe we can do a better job while cutting team size by half. I’ve built the foundations of the platform to make it happen (or not).
Full disclaimer: I had the luxury of starting from a blank page. I’m building a tool for a small, friendly audience with the goal of bringing perspective to our data, not a SaaS chasing product-market fit or built to scale teams worldwide. My experience is nothing like that of a typical engineer in a scaleup, where fucking it up carries far greater consequences. My codebase is also nowhere near the size most companies have to deal with. Let’s acknowledge that I’ve already eliminated 90% of the difficulty and enjoy the best setup to vibe-code comfortably.
Here is my journey.

How We Do (my 50 cents)
Back in Seoul, in my chicken coop, I decided to start from a blank page, leaving migration for later. My goal was first to be able to aggregate information in whatever shape and from whatever source it came. The good news is that LLMs are exceptionally good at handling large amounts of unstructured data. Even though we work in finance, our job does not always require ultra-precision or extreme consistency. What matters more is developing a sharp understanding of trends. We need to quickly spot data points in a vast, ever-shifting cloud to build conviction.
Without overthinking or making a plan, I started with a Telegram agent connected to Pipedrive, since Telegram is our team’s hub and my biggest frustration was getting to data fast without Pipedrive’s (old fashioned) user’s experience. It worked so quickly that my ambitions grew (insert *Villain’s evil laugh* here). Why not build a full web interface to replace most of our use of Notion or Google Docs - keeping only the features we actually use, for a snappier, more comprehensive experience, and without being limited by someone else’s roadmap?
So I started laying the foundations of a polymorphic knowledge base, accessible from anywhere, able to ingest any kind of resource, and extract intelligence from it systematically. Articles, discussion logs, pitch decks, screenshots, curated newsletters, even a tweet or a Reddit thread, plus essentially every relevant email and document we wrote or received: the key is to collect at scale what we consider strong proxies for valuable information. This also includes our private Discord community, reg.exe, where 260 tech founders and AI leads from around the world discuss new trends, share insights, and celebrate achievements daily. Knowledge is everywhere, and we capture it automatically whenever we find it. And since AI agents aren’t flawless, I built our own Chrome extension, tightly integrated with our workspace, which lets us quickly start a note from a calendar meeting or flag a discussion if it hasn’t yet been detected by our crawlers.
This is our cloud of information, an unstructured stream of curated content from engineers or journalists, constantly on the edge of innovation, from which we extract structured, sourced and weekly memos to help us, our founders, and even our LPs nurture their decision-making process.
Information > Data
Let’s put aside purely deterministic needs (financial transactions, for instance) for a minute. Computers led us to treat information (processed, organized, meaningful facts) as data (raw, unorganized facts and figures, meaningless in itself), because that was the only form they could handle. Forcing knowledge into a rigid taxonomy has always been a nightmare. The moment someone decides to tag their “green” companies as Climate Tech instead of Sustainable or Environment Friendly, your beautiful cog machine starts to cough. A human would naturally make the connection. A pre-LLM ERP or CRM would not unless specifically asked to. NLP, until recently, was little more than turning natural language into SQL queries: in other words, translating information back into data.
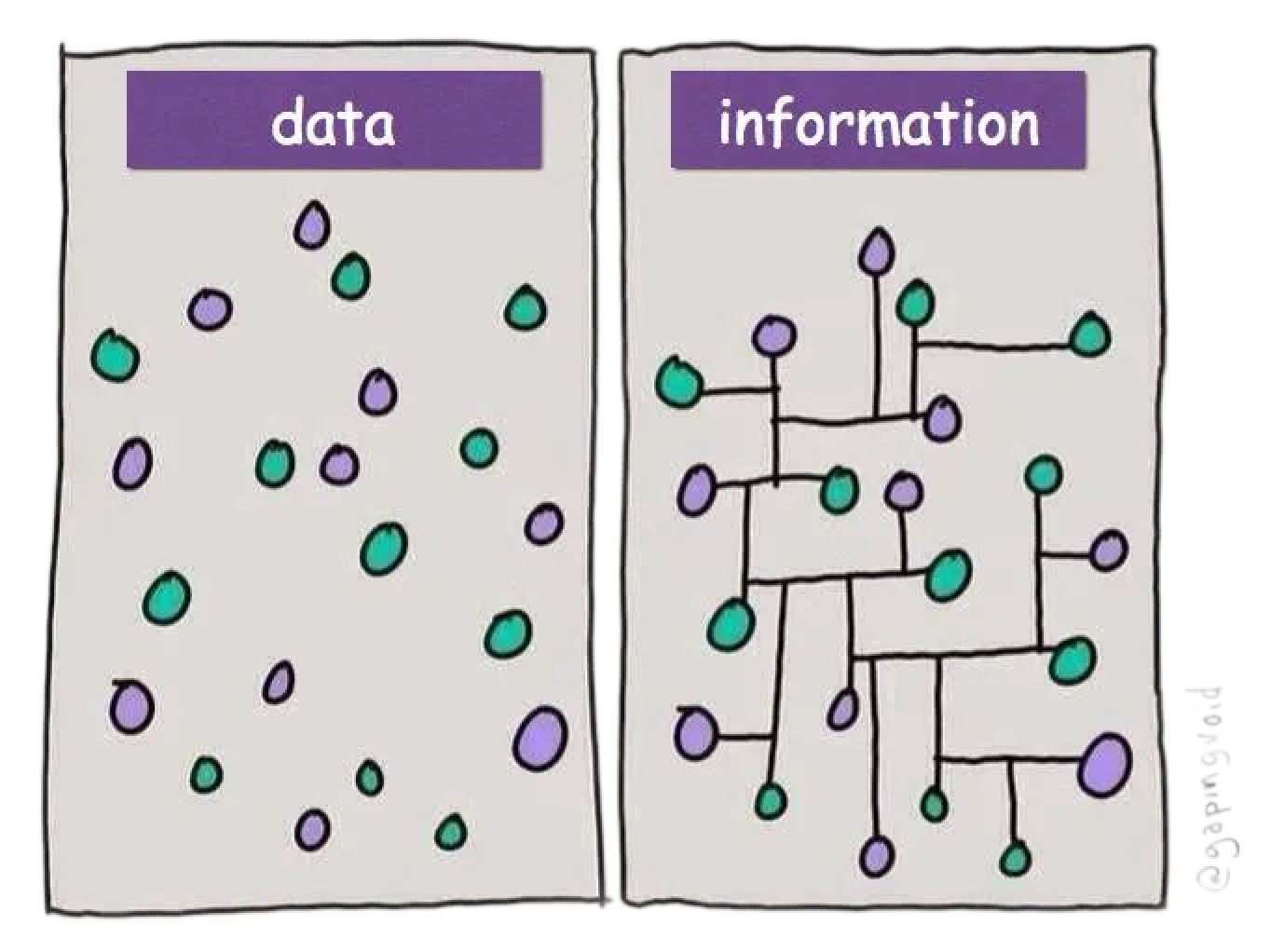
LLMs are not perfect, but the same can be said when working with people. They’re not always consistent, though often in ways more subtle than binary code. Also, scaling vectors is far easier, and how we leverage them is getting insanely good at a rapid pace.
So I decided to embrace this philosophy for our intelligence. We would rather not always get the exact same result twice, but gain a more forgiving scope of knowledge, instead of letting something slip through the cracks just because of a new way of coining terms. The beauty is that it also allows our portfolio and our LPs to benefit from this knowledge base, and refine it as a group, not by a data scientist.
Designing at LLM Speed…
Frontend-wise, I spent countless hours iterating on our future workflow, meaning the proper user experience. That’s probably where the biggest chunk of tokens went, and I probably had a bit too much fun doing it 🙈
Back then, we sketched doodles on paper, then moved to whatever design tool was trending at the time: Photoshop, Balsamiq, InVision, Sketch, then Figma. That step was usually unavoidable, because building in code used to take time: changing your mind on the flow meant losing hours, and your laziness (or your front-end developers team quitting) could easily cap your imagination. That’s why most design tools offered some way to showcase animations, with limited prototypes, dummy data, or Lorem Ipsum gibberish.
But I was alone, with less than 30 days to rebuild our team’s entire backbone. I was looking for a quick, painless way to turn that meh design into something elegant without sinking time into it. First, I asked Claude to use Google's M3 foundation (the latest Material Design), which was an improvement since it gave a bit of logic between screens, then I thought about sending screenshots of SaaS I find functional, minimal and pretty. So I grabbed a random screenshot of Folk in an article, shared it with Claude and let it work. My design was 80% done - a close-enough clone of a clean SaaS - in a single prompt, while I was sipping a Matcha Latte.
That blew my mind. Figma had been my best friend for years. I had it open even for the smallest, most trivial tasks, and suddenly it felt unnecessary for designing interfaces.
…And Unhinged FrUXstyling
The design is only a tiny part of the user experience. And even if I have been working on web products my whole career since the late 90s, anticipating the user flow, writing all the specifications, designing every tiny bit of interface before launching the production has never been my forte.

This new paradigm basically brought me back to enjoying the whole process like a kid unwrapping a Nintendo Sixty-FOOOOOOOOOOUR on Xmas morning. If you have enough cash for the tokens (more on that later), you quickly feel like Neo.
Building with tokens unleashes your creativity: and you can spend as much time refining a feature as you want until it feels perfect to you. For instance, while working on the Chrome extension, I figured it might be cooler to turn it into a proper application with Electron, even though I’d never built one before. All I had to do was ask Claude Code to convert my half-baked extension into a proper Electron app (with a refactor and cleanup of the legacy, of course), and then enjoy another Matcha latte. Being able to change direction instantly, without reading a line of documentation, without hearing a sigh of disapproval, simply after a short discussion with your IDE, gives you a real god-mode feeling. [At least, at the beginning 😇]
In just a matter of days, I set the foundation for a Telegram assistant, a web app, and a desktop app, while ditching Figma, Notion, Slack and Pipedrive. Not bad for a fistful of tokens.

One Stack to Rule Them All
Vibe-coding is also perfect for experimenting with tools to build your own. No need to dive into documentation—just throw it into your IDE, “talk through” whether it’s a good fit, and ask for alternatives. Once you’ve made your pick, all that’s left is creating an account and dropping the API_KEY into your .env file.
So before I take you through the rest of my journey, here’s my current stack, you can give them a try yourself:
Backend
🗄️ Supabase for the structured data (and more). To be honest, I find their GUI cute but annoying and pretty slow. Some operations, such as ALTERs, take too long, even on empty tables, and using queries is always the best option. Still, Supabase offers out-of-the-box a myriad of practical features around the data stack to build faster. I use it for authentication, object hosting, image resizing, and I also rely on Supabase Edge Functions as a powerful extension to PostgreSQL triggers.
🧠 Orq.ai is our AI backbone. Since everything relies more or less on AI, I make extensive use of models and prompts as glue between bits of code. This glue needs to be evaluated and refined continuously, and Orq is our gateway, almost the sole entry point, enabling non-technical team members to make those changes seamlessly. From embedding, to hybrid search, information extraction, RAG: almost everything is Orqed.
🔮 Mem0 helps our agent (via Telegram for instance) to provide a conversational experience. It keeps memories as you use it, previous discussions, specific details, some preferences. Orq will add this layer soon. In the meantime, I am using Mem0 which works out-of-the-box. I never had to get back to it since the integration.
🏠 Koyeb for hosting. I initially started the project in a serverless environment on Cloudflare Workers. It turned out to be a pain in the ass most of the time. Koyeb, on the other hand, delivers the smoothness “aux petits oignons” of what serverless should feel like from a user’s perspective, with the advantage of a self-hosted environment and at the cost of bare metal. We also use their database service for some backlog features since disk storage is unlimited.
⚖️ Shipfox is handling all our CI, and it’s absolutely critical as I enter the production phase. Building fast often means regressing twice as fast: LLMs have no pity for past code and lives in harmony with chaos. Shipfox doesn’t just cut down the cost of CI time, its dashboard gives me the visibility I need to spot flaky or unreliable tests. A common pain point as test suites grow, especially when you’re not the one writing them. Shipfox integrates seamlessly with GitHub Actions, and switching to it was as simple as changing a single line of YAML.
APIs
🌎 Linkup is our access to the outside world. All our notes and memos can be enriched with open data, and Linkup provides a simple yet powerful API that crawls and retrieves information in real time with the power of LLMs. This content can even be delivered in structured outputs, fitting seamlessly into templates. I’m probably only using 10% of Linkup’s potential, and there are plenty of features still to build with it.
🐝 ScrapingBee is our scraper. Every link attached to our notes or memos, every newsletter we receive, every article we bookmark, and all content shared on our Discord is (or plan to be) automatically scraped and added to our knowledge base. ScrapingBee is powerful enough to bypass most trackers.
🕵️♀️ Notte.cc is our smart scraper. It lets us navigate websites and extract information intelligently with prompts. Notte is freeing you from painful regular expressions, flimsy scripts and shitty parsers, and it behaves like a human would, only at scale.

Frontend
🎨 Storybook is a great way to keep the AI in check and establish a common language with it. It’s very popular among human teams, and collaborating with Claude is no different. You can have it generate stories for each component, giving you a clear, practical and beautiful portfolio to reference when requesting new styles and features. Thank you, Robert Hommes, for putting this on my radar. I wish I had started with it sooner.
🤝 Tiptap is a “headless, framework-agnostic rich text editor” built on top of ProseMirror, offering an out-of-the-box Notion-like experience. You can use it as an open-source library, and it already does a great job: pretty, highly configurable, and with a cloud-hosted version that adds powerful live-collaboration features. Karim Matrah from Contrast also shared great alternatives in that space: BlockNoteJS and Liveblocks.
On its way
🧠 Lettria will soon upgrade our standard RAG into a Graph RAG. By combining graph capabilities with the power of vectors, we’ll be able to extract information with much greater accuracy and be (almost) free from hallucinations. We are currently carefully selecting the content that will serve as the foundation for our ontology.
🔎 Meilisearch for AI search. Honestly, Orq.ai is already handling perfectly the hybrid search, but I’ve heard so many great things about Meilisearch’s user experience (ping Gilles Samoun) that I decided to connect their API to experiment with it. I won’t keep it in my stack, but developers looking exclusively for a search engine API should definitely give it a try.
🛟 Plakar, for peace of mind. History has shown time and again that shit happens, no matter how big you are, no matter how good your infrastructure or code may be. And since we’re neither big nor am I particularly dedicated, focused, or talented, I need something both bulletproof and effortless to set up and restore. Therefore, Plakar is the way.
🎛️ Alpic to tinker a bit with MCP, integrate parts of our platform into Claude and ChatGPT directly, replace our Telegram agent, and see how far we can push the boundaries.
Enchanted Deceptions
I started this journey with Cursor, tried many other flavors of VS Code (see below: Game the Same, Just Got More Fierce) but spent most of my time with Claude Code. All these tools are absolutely magic, and the choice is (almost) entirely subjective.
When using Cursor, I was still a bit hands on. But quickly, I’ve switched to full prompt and probably wrote fewer than legit ten lines myself (changing a few Tailwind tags don’t count). 99.9% of the coding was done through AI. That doesn’t mean it was 99.9% painless. Hell no. It ain’t all magic: programming models are a great tool for people with coding and good technical architecture knowledge. People who are willing to dive into the weeds when needed. If you know nothing and don’t understand what the AI is telling you, and you can’t guide it from time to time, you can quickly end up in a costly spiral of death, burning tokens (and your mortgage savings) while Claude loops endlessly over something stupid and/or impossible. And this happens A LOT.

LLMs are not (yet) autonomous engineers. So the larger the codebase grows, the more the IDE requires precise instructions, clear scoping, and close monitoring to avoid damaging the foundation. Keep in mind: if LLMs are amazing at building things fast, they carry just as much destructive power, if not more. So far, Claude did 80% of the heavy lifting for me. The remaining 20% demanded far more guidance and were sometimes so painful, so extreme, it felt like being a babysitter on the verge of murder. I could’ve written more code, but I find it difficult to co-write with an AI, and I decided to focus on the logic and the data structure instead.
In Prompt We Trust
People say a good prompt is the path to success. It is true, but to be fully honest, I was not obsessed with it. At first, I used Claude Desktop to draft a plan before pasting it into Claude Code (benchmarks say that you need to feed models with their own dog food). I eventually settled into a half-baked routine: putting Claude in “plan/pause mode,” where the model is only allowed to browse files, do its research, prepare a strategy, and throw out ideas without discrimination: something major, structural, then 10 useless details as they come. Then I let it refine the plan through discussion before giving it a go. It’s a messy back-and-forth where I let the structure emerge with the flow. Hardly the best recipe for clean code straight out of the box, and some people far smarter than me have turned prompting into a science (check out Gabriel Olympie’s PromptServer, for instance). But the good thing about vibe-coding is that nobody’s there to judge you.

Fifty Shades of Technical Debt (And Then Some)
Sadly, going full-throttle on vibe-coding comes with more than just the cost of tokens. Soon enough, you feel like Dr. Frankenstein, stitching together isolated bits of code. And the more you build, the heavier the weight of technical debt becomes, revealed through hundreds of inconsistencies. Some are visual (different button styles, mismatched font sizes and colors you never asked for), others functional (z-index chaos, redundant decision trees across the repositories leading to inconsistent behavior). Even if you’re not the one coding every line, you can still feel your amazing project starting to drift south after only a few days. Think of your AI copilot as a junior developer who behaves like all LLMs: very proactive (sometimes too much), eager to please, a bit too obsequious, and occasionally forgetful.
The way to mitigate it is the same as with humans: (ask it to) write logs for debugging. (Ask it to) write specifications once you’re satisfied with a result. And (ask it to) document thorough postmortems while the context is still fresh, so it doesn’t fall into the same pitfall twice. This becomes even more useful when you have multiple apps and repositories, as I do. They all need to communicate heavily through APIs. The more context you give the AI, the more efficient it becomes, and the happier you’ll be.
On top of these good practices, nothing beats proper testing, especially on the backend. You can survive a missing overlay or a visual inconsistency, but you don’t want to risk losing real information or leaving a huge backdoor open. In a way, the major discovery is that whether it’s a human or a machine building, the guardrails stay the same.
The Cost of Doing Business
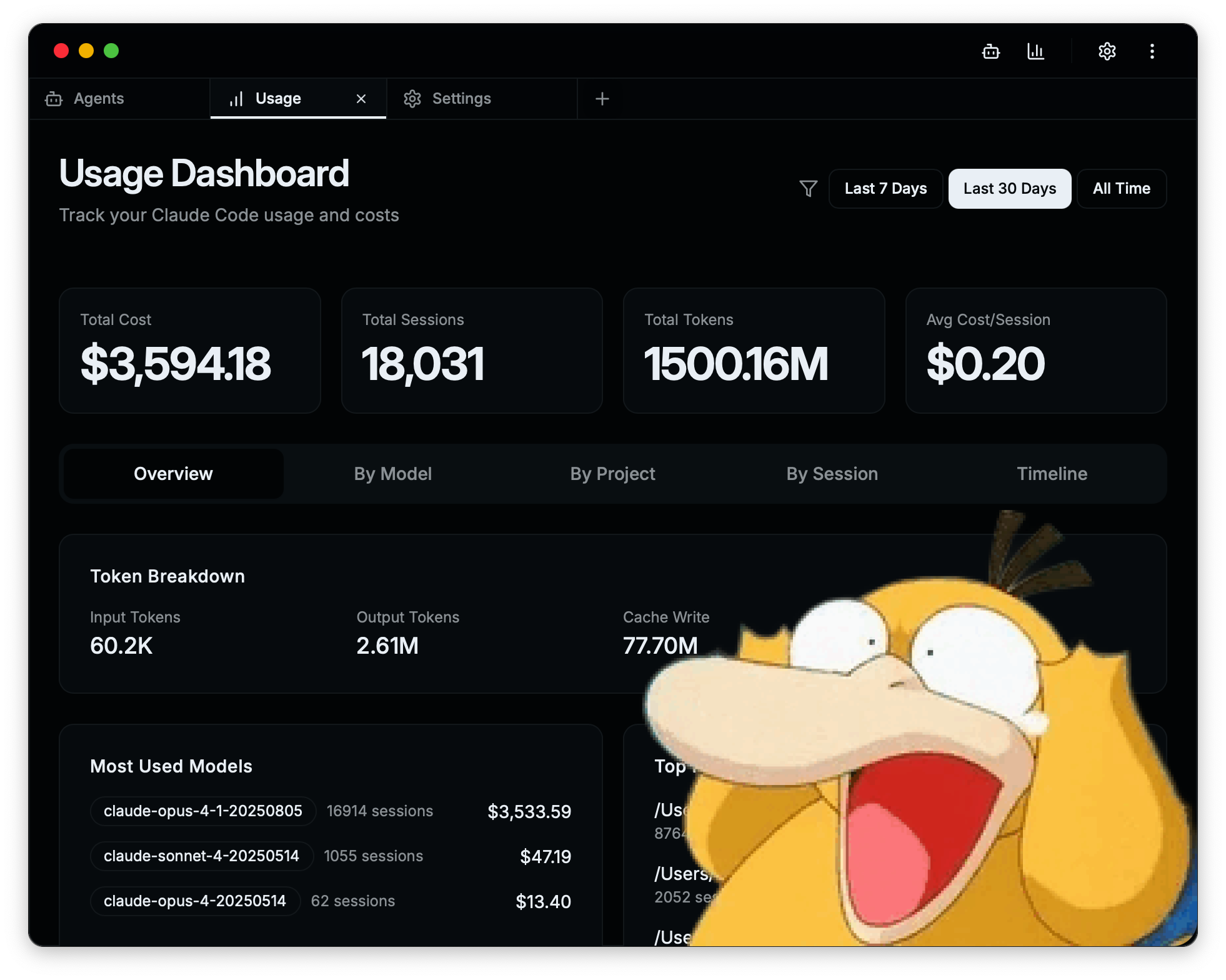
For almost an entire month, Anthropic unexpectedly allowed me to use the $200 Max 20x plan from Claude Desktop on Claude Code way beyond any reasonable level of consumption. Between August 4th and 22nd, my usage added up to roughly $2.6k in token value. Then I was notified that I’d be downgraded from Opus to Sonnet (The quota system keeps changing, and the latest update, I believe, provides 40 hours of Opus and 480 hours of Sonnet per week with Max 20x) with both speed and quality taking a hit. It feels like that first $200 entry point is a first dose of crack. Claude is the pusher, me the drug fiend. Now, to keep the rush going, I need to use the API and pay per usage instead of a flat monthly fee. In that mode, you’re basically topping up $100 multiple times a day. At my pace, that meant about once every three hours of work. Was it worth it? You’re goddamn right! Even if I could have made my token consumption far more efficient (see below: Garbage In, Garbage Out).

Game The Same. Just Got More Fierce (*)
In just a few weeks, I’ve already cycled through five different tools, hopping from one to the next without needing to configure parameters or adjust the way I prompt. And that’s not even counting the asynchronous agents I briefly tested, like Jules (Google Labs) or the very early Ariana.dev. By contrast, in my 25 years in tech I’ve only seriously used five code editors. These days, I can barely tell you what I’ll be using next week.

Within a few days, Alibaba released Qoder, another promising VS Code fork. They launched with a free plan capped at “2000 credits” (whatever that really means), clearly aiming to capture a share of the agentic coding market. Kilo Code followed, announcing - like many others - a 7 day uncapped free access to Grok Code Fast (aka Sonic). Meanwhile, OpenAI announced significant improvements to Codex - after a rather chilly reception - reportedly leading to people ditching Anthropic’s Opus, still considered the top performer but at a steep cost.
And that’s just one week in the coding tool landscape.
Just a Few Takeaways From Your Average Joe
I’m going to repeat myself, but it’s worth reiterating that starting from a blank page is very different from dealing with legacy code in a stressed production environment. After just a few weeks, I felt the urge to clean up and streamline, and I spent days refactoring my spaghetti code with Claude. For instance, the mix of Material Design, migrated half-way to Tailwind’s standard ended up in a complete abomination. But even in this case, I managed to (painfully) prompt my way out.
Overall, LLMs aren’t yet at the point where they can replace all engineers. But I don’t doubt they will be soon enough, and in the meantime, they just can’t be ignored. I’ve been able to achieve so much in so little time, and avoided most of the excruciating parts (writing specifications, reading documentation, state management in React, and basically anything frontend & UI-related) while enjoying the fun ones (tinkering with UX, data pipelines, experimenting great tools, and pretty much anything backend-related).

Speaking of documentation, it has never been more important, not so much for humans but for LLMs. I’ve noticed in particular that Claude tends to use REST APIs by default and never looks for the SDK unless you give it the link to the repository. Which probably means that most apps are not highlighting their SDK enough. Also, please refrain from relying on screenshots to illustrate instructions, since images are hardly analyzed by agents.
I’d recommend that you try it yourself by feeding your documentation entry point to all AI-powered agents and see how well it holds up. In a way, this is a blessing, since you can now run user testing without even talking to your customer.
Garbage In, Garbage Out
Vibe-coding is really fun, and this has been the best vacation I’ve had in a long time. It emphasizes building over coding, and I realized that’s what I actually enjoy the most, and what I was missing so much. Since it was summer break and I had no clear objectives, I freestyled with absolutely zero planification, and I’m paying the cost now as the product inches toward a production-ready form.

The last time I wrote decent lines of code was years ago. The god-mode I was in led me to parallelized far too many projects, and changed my mind on the architecture repeatedly. But I have no regrets: it was mad fun, and I learned a lot. Nothing teaches you more than a two-day streak fixing a feature made of spaghetti code, born from hundreds of tiny, shitty prompts. Many times, I got very mad at Claude, and you could hear me insulting it, but of course, most of the shortcomings were mine. Garbage in, garbage out, as Sohrab Hosseini from Orq.ai reminded me when I was complaining about the early hybrid search results.
Sadly, the fun I had multitasking between projects didn’t translate into quality code (as you’d expect). Letting the AI make architecture choices, stumble over the same problem ten times, not reading properly, not guiding it carefully, that’s probably my biggest mistake. Writing the code isn’t the hard part and the AI is pretty good at spitting that out. The real work is writing down the process, iterating in discussion mode until everything is crystal-clear and unambiguous. Sure, 80% of the codebase came from the AI - the boilerplate, the obvious stuff. But when it comes to the spine, where the data goes, how it’s altered, how it’s passed between components and libraries, the AI is usually fucking clueless. And worse, it’s perfectly happy to write the same thing twenty times in different places, each with minor differences. A recipe for disaster.
Build or Buy (Buy)
Even though I’m on a quest to get rid of our suite (Pipedrive, Notion, Slack, and the rest), it’s still preferable to outsource certain services, even commercial ones. AI can read documentation and generate small bits of code almost flawlessly, making it the perfect glue. But whenever I needed to code something even slightly subtle, I probably should have started by looking for an existing library, and ideally a hosted one.

For instance, it took me days to build a full collaboration live system for our memos using the open-source library Tiptap as the WYSIWYG editor. It was fun, but ultimately a waste of time, without coming close to delivering a user experience I could be proud of. I eventually switched to the Tiptap commercial version (Tiptap Cloud), which takes care of everything seamlessly — WebSocket server hosting, maintenance, logs, and more — for shy of $50 a month. In my situation, that choice was a no-brainer.
Choosing Supabase, Orq.ai, or any of the aforementioned tools follows the same logic. Yes, there are plenty of open-source solutions. I’m not trying to save money at all costs or reinvent the wheel: my goal is to build the best bespoke user experience. And cost-wise, I reckon it’s still cheaper to pay for a handful of APIs than to pile up individual licenses for each of us. I’ll do the math later anyway.
Just Getting Warmed Up
I don’t really have a conclusion yet, it’s still the beginning of this journey. Next, I need to migrate the data from Pipedrive, merge the dozens of sources mentioned above with years of backlogs, and build our knowledge graph with Lettria.
And I don’t expect the result to be perfect on day one, far from it. I still have a lot to learn, many evals to design and run, architectures to test, and an exciting journey ahead. I also have five repositories, only one of which is fully functional. AI or not, the last mile is always the toughest. Still, gathering information in a semi-structured way is giving me and my team an incredible sandbox to put our readings and knowledge to the test.
This fresh start will nurture our mindset and, hopefully, give us an edge as a VC firm. This job is about connecting with people who thrive on innovation. I believe this early draft of a platform will be a means to spark discussions and foster collaboration, especially with engineers and researchers. And as modest as my project is, building on the side helps keep me actively involved in this revolution rather than just having a passive/observer role. Does it make me/us better investors? Who knows. But it’s certainly more interesting and fun, and it will give us many opportunities to share the lessons we picked up along the way.
May those lessons be many 🙏
🙏 PS: This vacation log is already too long, and I still have plenty to say and refine before I can share a result I’m satisfied with. Give me a few weeks, and I’ll return with a thorough update, including a 📊 financial analysis of both building and running costs. Stay tuned.