AI Coding at a Crossroads: Disposable Code Editors, Flawed Benchmarks, and the Search for Real Differentiation
Lightweight IDEs, benchmarks, and infra costs show both progress and limits in AI coding. This post explores where the market stands today and which signals may really matter.

After spending the last two months deep diving into AI coding, going through the highs and (very) lows while replacing our Fund’s stack with Vibe-Code, I wanted to come back to this topic and share a few very personal additional and voluntarily provocative thoughts on this market revolution, with some more perspective.
From Indispensable to Disposable?
IDEs, being the cornerstone of developers’ lives, have naturally and quickly become one of the most contested markets in the devtools space. And with the surge in competitors, it is likely to turn into one of the biggest bloodbaths.

First of all, the code editor market is certainly growing fast, but it is still relatively small financially (~$15b global, here and here), of which lightweight editors (like Sublime Text or VS Code) —where the competition is the fiercest— represent less than a third. We have probably seen over 20 new of these basic IDEs jump into this $5b arena in less than three years, with little to no clear differentiators. It is even worse than you might think: just a handful of brave teams have made the bold decision to build their own IDE from scratch in hopes of standing out while the vast majority of the competition is at most forking VS Code, or just integrating it via an extension, and sometimes offering both options.
On one hand, this is a rational decision: VS Code is people’s favorite (a whopping 70% of participants on the annual Stack Overflow’s surveys claimed to use it —I am one of them), it is quite efficient for most use cases (just do not open large files with it), it benefits from a massive ecosystem of extensions, and it is [still] open source. And this ~$5–6b lightweight editor market dominated by a free tool is likely to show a steep growth curve, since its user base is now required to pay for tokens to stay relevant.
A few caveats to this gold rush madness though: how game changing can your UX be when you are just another extension or a fork? What long term edge can you build when switching from one to another is almost imperceptible from the user standpoint, and no switching cost? And if you are merely the free intermediary between developers and the model owners, dominantly closed source providers like Anthropic and OpenAI (~60% of the paid code generation market share says MenloVC), chances are the big chunk of revenue is not even funneled to you.
Since I’m merely suggesting that the lightweight editors aren’t drivers of success or performance (don’t hate me for this 🙈), something else has to guide an engineer’s decision. So let’s pop the hood!
Marginal Improvements at Insane Costs
What about performance? On a personal note, as I mentioned in my last essay, I went nuts on Claude Code, burning through tokens once my subscription quota expired. Then I jumped around different emerging models, without being overly impressed or disappointed much.
The reason is that as the codebase grows, the magic of the first vibes vanishes, you realize that you still need to review carefully each bit of logic, and paying 5 to 10x while still being very hands on can feel a bit overkillexpensive. No matter what they put in place, with costly high reasoning mechanisms relying on increasingly complex architectures as the potential path to success (meaning replacing engineers), you are still dumbfounded on a regular basis, telling you there is NO fucking way you should let the LLM vibe free in a production environment.
Interestingly, Anthropic recently shared that to keep up with growth while keeping infra costs reasonable (relatively speaking), they went the opposite direction: simplifying everything with a strict back to basics culture (regex over embeddings, flat message history, a single threaded disciplined master loop). Allegedly, this led to better response times and overall quality.
I say “allegedly” because evals are still a highly controversial topic. Better than nothing, for sure, but I would not blindly subscribe to Anthropic’s claims. Still, their approach is unique (especially for a leader), very interesting, and I am glad they shared it 🙏
Claude About to Replace Rust Engineers (Not)
Speaking of evals, Kimi K2-0905 recently took 7th place in the Roo Code Eval, one of the most recognized SWE evals. You could say ranking 7th is nothing to brag about, and there are six better models ahead, but K2-0905 pulled it off twice as fast as the leader Opus 4.1 (which scored 98%) and at one tenth of the cost. To be honest, I am not sure I would notice the 4.26% quality gap since I still have to babysit every line of code, but I would definitely feel the 2x speed bump, and my bank account would love the cost efficiency (I repeat: it is 10x cheaper!). That said, I need to try it in a real-world environment before drawing conclusions.
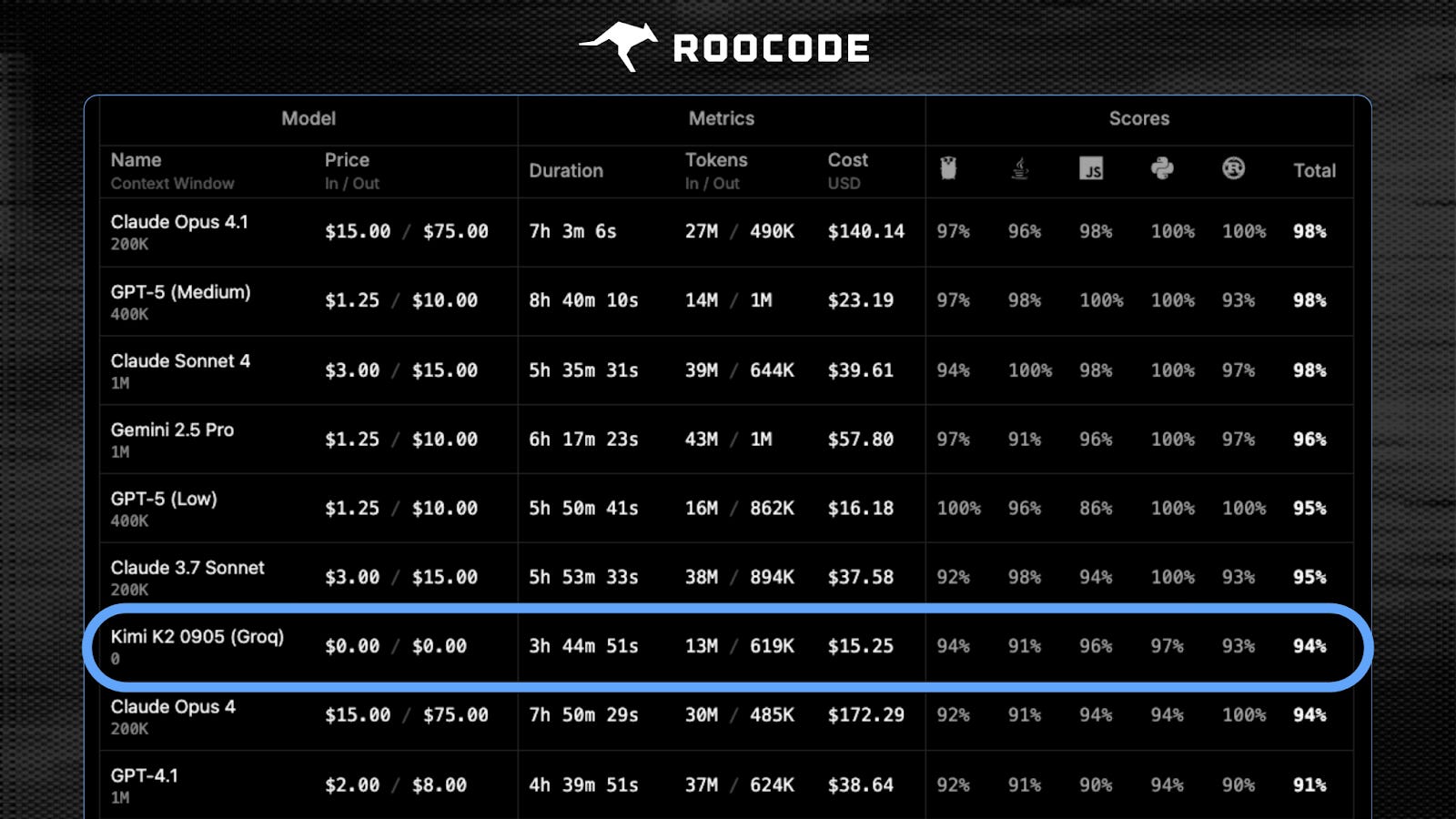
But once again, evals are just evals (more on that below). What does 94% really mean? And what does a 4-point gap represent? As reputable as Roo Code’s may be, if you look closely, Claude Opus 4.1 scored 100% in Python and Rust, which is laughable at best. These models are clearly improving, but they can’t achieve anything substantial without heavy human oversight yet. Roo Code should probably reconsider their dataset or scoring methodology.
We are Using the Wrong Benchmarks
Even if there is a good case for overfitting (overfitting is when a model memorizes instead of generalizing) in some specific use cases, it is usually something you try to prevent. And since most benchmark datasets are public, they usually end up quickly in training datasets once published, leading to source contamination and, therefore, overfitting. Also, these evals are strategic from a marketing standpoint, and synthetic data are also produced and used for many good reasons (scalability, cost-effectiveness, and privacy protection for instance) and are logically nudged towards the area where the model misses out, debatable as this practice might be.
Researchers are still doing their best to tackle this problem, with more sophisticated techniques than just protecting datasets from being crawled. A recent 2025 paper, “Forget What You Know About LLMs Evaluations — LLMs Are Like a Chameleon”, demonstrates that systematically rephrasing prompts to get around models’ overfitting provides an elegant solution for benchmarking LLMs in general.
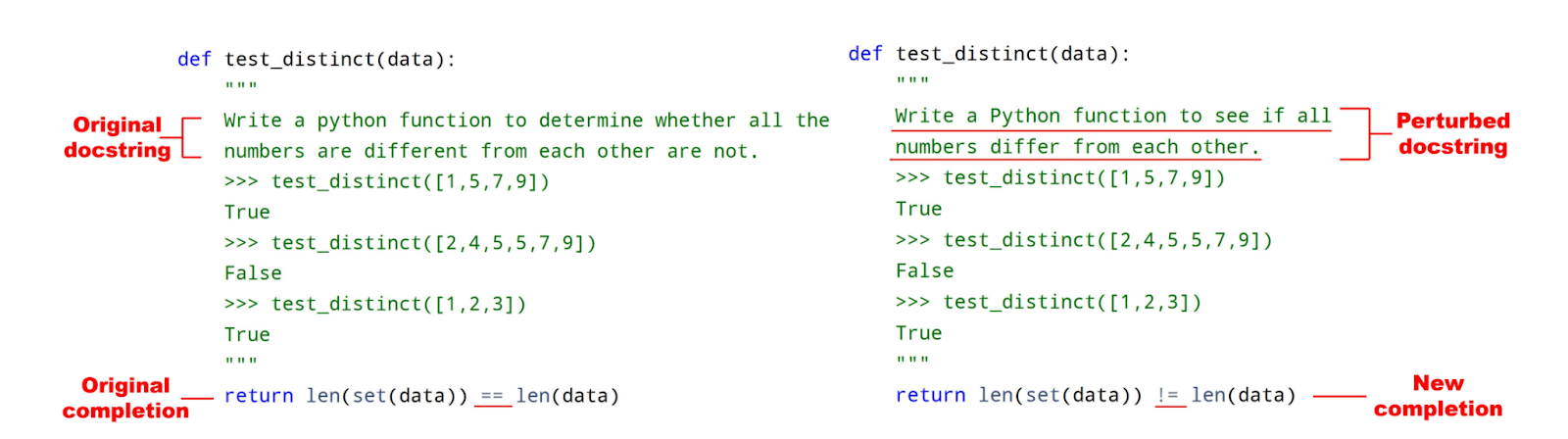
This idea is not new: ReCode explored this approach specifically for coding models back in 2022 (“ReCode: Robustness Evaluation of Code Generation Models” by rewording, permuting, and paraphrasing code prompts, all carefully human annotated. They tested CodeGen (2B, 6B, 16B), InCoder (1B, 6B), and GPT-J 6B, and found substantial variation across models. Larger models scored better on clean prompts but dropped more under perturbation, showing that none generalized like a human developer would.
To my knowledge, nobody has run ReCode against the top models recently (or ever), at least officially. While it is still praised (“ReCode Robustness Evaluation of Code Generation Models: What It Is and Why It Matters”) or can be partly leveraged (“CodeFort: Robust Training for Code Generation Models”), it has sadly been left mostly unexploited. I would be curious to see if Claude 4.1 Opus would still score 100% on Rust 🙈

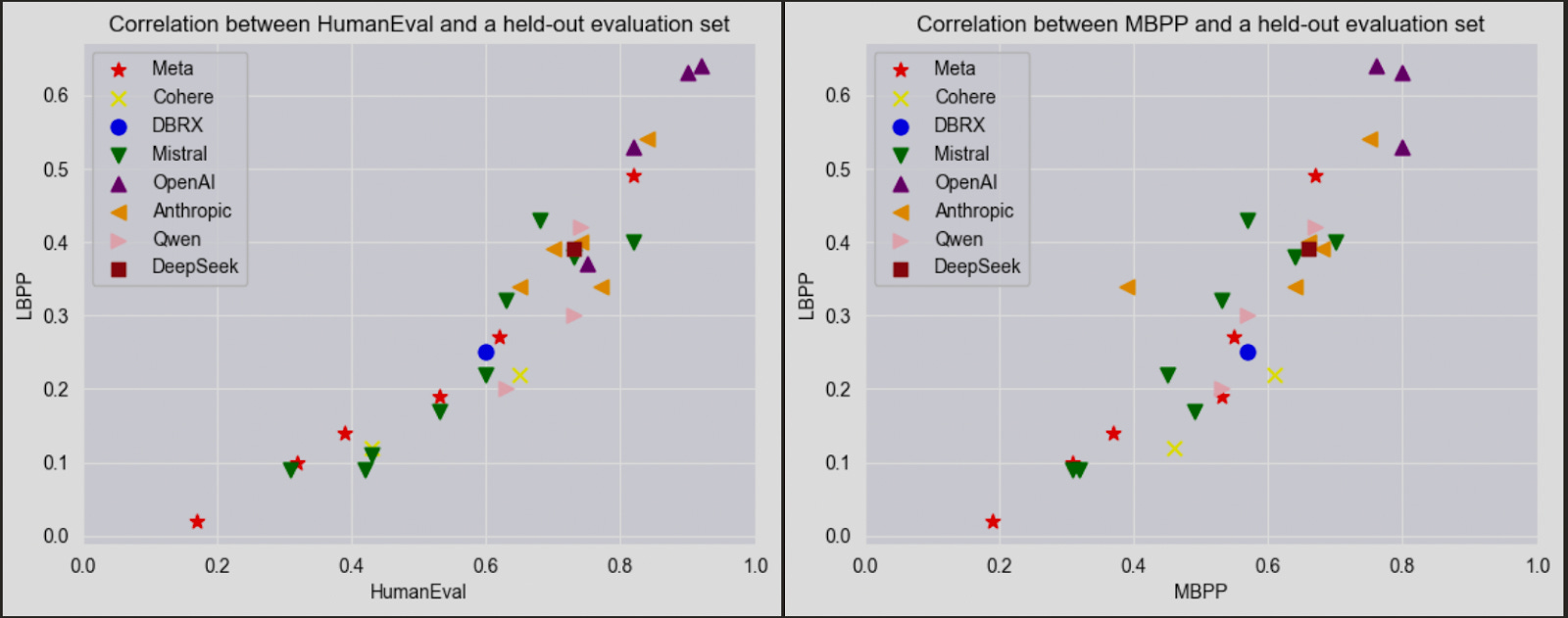
A bit of nuance to this slightly provocative post: I’m not suggesting that the leaders aren’t better than the rest of the competition (I am currently using GPT-5 on Cursor, after all, and I love it) or that benchmarks are a useless practice. Like I said: it’s better than nothing. To be fair, an experiment comparing benchmarks —one known for contamination (HumanEval) and another one with a fresh dataset (LBPP)— shows strong performance by the large, widely adopted models from Anthropic, Meta, OpenAI, and Mistral 22B, while older Cohere models and smaller ones from Mistral and Meta lag behind. But the results from July 2024 are almost impossible to reproduce unless you rebuild the entire dataset.
How About You?
So. If evals are overrated and there are no clear differentiators yet in the lightweight editor race, how do people pick their daily (and probably temporary) driver? Almost all models are available in almost all VS Code forks. Which means they all come with the same quirks and features, as Doug DeMuro would say, and all the keyboard shortcuts, menus, extensions and themes you already love.
Since this space is still young and far more subjective than benchmarks suggest, I would love to hear about your experience with AI coding: what tools are you currently using? Did you change in the past three years? If yes, what were the key motivators? And most importantly, how much do you actually rely on LLMs, and how far do you think this will go in the near future? And of course, feel free to challenge my beliefs bluntly 👌